
Thermodynamic Computing and Transformers
Do thermodynamic systems have the potential to revolutionize the AI space?
In the recent past, the performance of AI systems has leapt forward considerably, with capabilities that seemed like science fiction now being able for fractions of a penny. For some this represents the beginning of a new technological revolution, The Artificial Intelligence Revolution, while skeptics believe that limitations exist that will prevent such a revolution from occurring any time soon. Available compute and energy are some of these discussed limitations.
As a response a new computing paradigm seems to be budding, thermodynamic computing, spearheaded by the company Extropic. In order to demonstrate the advantages of their thermodynamic computers over classical computers, particularly for AI, this article outlines the (simplified) steps involved when running a large language model on either system. In the final section, the steps in which the advantages of thermodynamic computers arise will be elucidated.
For further information, Extropic should be releasing details on their full-stack by the end of 2024.
Why GPUs are Popular in AI
Graphics Processing Units (GPUs) are responsible for displaying the content on the screen you're currently reading this on. GPUs quickly perform an immense amount of calculations to determine the color of each pixel on your screen. A computer's central processing unit (CPU) is not able to handle this large volume of calculations well as it lacks cores (i.e. processing units that can independently perform calculations). A GPU on the other hand has orders of magnitude more cores than a CPU thus is well suited for handling the large volume of calculations necessary to display content on a screen. Due to this capacity to handle a large volume of calculations, GPUs have become incredibly popular in artificial intelligence (e.g. large language models like OpenAI’s GPTs) which also requires a large volume of calculations.
Classical Computing vs Thermodynamic Computing
Classical computing involves a system that performs calculations by encoding information into 0s and 1s (i.e. binary) via transistors which can be in an “off” state (i.e. 0) or in an “on” state (i.e. 1).
Thermodynamic computing does not encode information into binary and instead performs by making adjustments to how energy flows throughout the computer and then measuring (i.e. sampling) how the energy ended up being distributed throughout the computer.
Classical Computing
1. Tokenization
The user inputs "Hello, world!" as a prompt. In order for the large language model to be able to process the prompt, it must first be converted into numbers (i.e. tokens). This process is called tokenization in which complete, words, parts of words (e.g. “able” in “doable”), numbers, punctuation, and more.
Example:
"Hello, world!" → [t1, t2, t3, t4]
Key:
t = token
2. Embedding
In order to capture the meaning of each token, the tokens are converted to vectors (a set of numbers) which correspond to their meaning.
Example:
t1 → [v1, v2]
Key:
v = vector
Only the first token will be used in examples for simplicity, however the same conversion would occur for all other input tokens.
3. Positional Encoding
In order to capture the sequence in which the tokens appear in the prompt, another vector, representing the position of the token is included with each embedding
Example:
[v1, v2] → [v1, v1] + p1
Key:
p = vector for positional encoding
4. Attention
In order to be able to focus on more salient parts of the input, calculations are performed on each embedding, producing attention scores. In practice, multiple attention scores (i.e. multi-head attention) are calculated for and then applied to each embedding in order to attend to each embedding in different ways (e.g. how a word fits into the immediate context AND how the word might relate to something mentioned several sentences prior). The resulting output is an embedding that is context-aware.
Example:
[v1, v1] + p1 → Head 1: [a1.1, a1.2] Head 2: [a2.1, a2.2] Head 3: [a3.1, a3.2] → [cae1.1, cae1.2]
Key:
a = attention score
cae = context-aware embedding
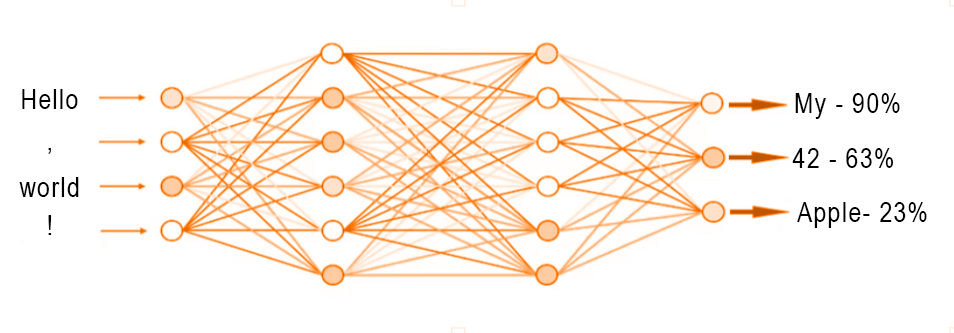
6. Neural Network
The resultant embeddings from the attention mechanism are passed through a neural network. This produces a prediction of the probability of which tokens come next. This is called a prediction score. A prediction score is produced for every token in the model’s token vocabulary (i.e. a list of every single token used by the model)
Example:
NN with 2 Layers & 2 Neurons
In reality there are many more layers and neurons
Layer 1:
Neuron 1:
Weights: [w1.1, w1.2]
Bias: b1
[cae1.1, cae1.2] → activation_function((cae1.1 * w1.1 + cae1.2 * w1.2) + 2.2) → [neuron1output1.1 , neuron1output1.2]
Neuron 2:
Weights: [w2.1, w2.2]
Bias: b2
[cae1.1, cae1.2] → activation_function((cae1.1 * w2.1 + cae1.2 * w2.2) + 1.1) → [neuron1output2.1 , neuron1output2.2]
[neuron1output1.1 , neuron1output1.2] + [neuron2output2.1 , neuron2output2.2] → [layer1output1 , layer1output2]
Layer 2:
Neuron 1:
Weights: [w1.1, w1.2]
Bias: b1
[layer1output1 , layer1output2]→ activation_function((cae1.1 * w1.1 + cae1.2 * w1.2) + 2.2) → [neuron1output1.1 , neuron1output1.2]
Neuron 2:
Weights: [w2.1, w2.2]
Bias: b2
[layer1output1 , layer1output2] → activation_function((cae1.1 * 1w2.1 + cae1.2 * w2.2) + 1.1) → [1.1, -0.3]
[neuron1output1.1 , neuron1output1.2] + [neuron2output1.1 , neuron2output1.2] → [layer2output1.1 , layer2output1.2]
…
Key:
w = weight
b = bias
7. Probability Distribution
The prediction scores for each token are converted into a probability distribution.
Example:
[layer2output1.1 , layer2output1.2] → [t1 , 0.70]
[layer2output2.1 , layer2output2.2] → [t2 , 0.01]
[layer2output3.1 , layer2output3.2] → [t3 , 0.02]
[layer2output4.1 , layer2output4.2] → [t4 , 0.65]
[layer2output5.1 , layer2output56.2] → [t5 , 0.68]
[layer2output6.1 , layer2output6.2] → [t6 , 0.59]
Only a few probabilities are shown for simplicity, however in reality a probability would be calculated for all tokens in the model’s token vocabulary.
8. Token Selection
The token whose probability of being the next token matches the probability that the user selected is chosen.
Example:
[t1 , 0.70]
[t2 , 0.01]
[t3 , 0.02]
→ [t1 , 0.70]
[t4 , 0.65]
[t5 , 0.68]
[t6 , 0.59]
9. Detokenization
The selected token is converted back to text, and then outputted.
Example:
[t1 , 0.70] → “I”
∞. Repeat the Entire Process
The entire process is repeated, but now with the newly predicted token. The process will continue to repeat until an end token is produced (or a token limit is reached).
Example:
“I” → “Hello, world! I”
Thermodynamic Computing
1+2+3+4 Tokenization, Embedding, Positional Encoding, and Attention
The first few steps remain the same when running a large language model on a thermodynamic computing as the requirement for numerical values is the same.
Example:
"Hello, world!" → → → → [cae1.1, cae1.2]
5. Energy-Based Embedding
In order to determine how each embedding will contribute to the energy landscape, a set of parameters are included with each embedding. This energy landscape will represent the probabilities of all of the possible subsequent tokens. A landscape of probabilities.
Example:
[cae1.1, cae1.2] → [[ebe1.1,p1.1] , [ebe1.2,p1.2]]
Key:
ebe = energy-based embedding
6. Basis Function Application
Various functions (i.e. basis functions) are applied to each embedding, each extracting different features and interactions from each embedding.
Example:
[[ebe1.1,p1.1] , [ebe1.2,p1.2]] → [[bfo1.1,bfo1.2] , [bfo2.1,bfo2.2]]
Key:
bfo= basis function output
7. Physical Implementation
The thermodynamic computer is composed of josephson junctions which are superconducting circuit components. These junctions superconduct as long as the current flowing through them does not exceed a given current (i.e. critical current).
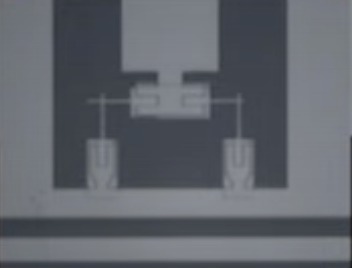
The critical current of each junction can be modified (such as with magnetic fields). When initially loading the model (i.e. energy based model), the critical currents of each junction are set to match the weights assigned to each basis function, thus physically encoding the model into the circuit. If a basis function has a higher model weight, then its corresponding junction will have a higher critical current set, thus allowing for a greater flow of electrons through it, thus increasing its contribution to the overall energy landscape.
8. Applying Embeddings
The embeddings are inputted into the system via modulations to the current and voltage at certain locations within the circuit.
9. Thermal Equilibrium
Electrons within the superconductive material naturally flow throughout the circuit and its josephson junctions. The distribution of electrons throughout the circuit is determined by the critical current of each junction, with a greater supercurrent of electrons flowing through junctions with higher critical currents. Eventually the distribution of electrons reaches an equilibrium where the net movement of electrons is stable (i.e. a thermal equilibrium).
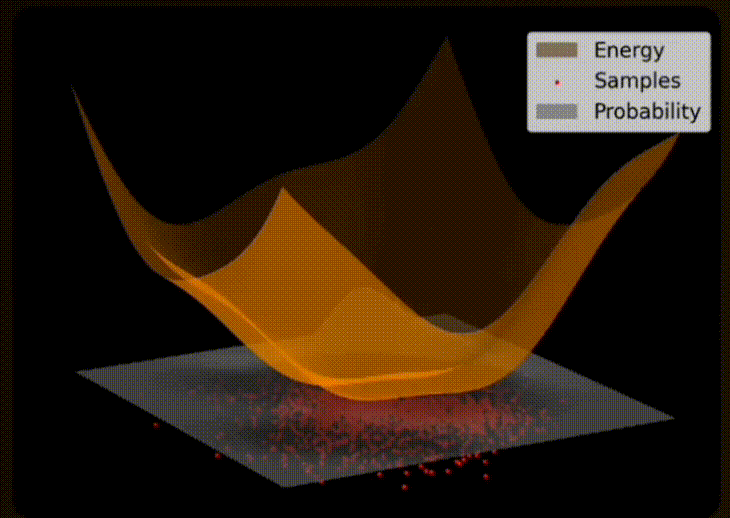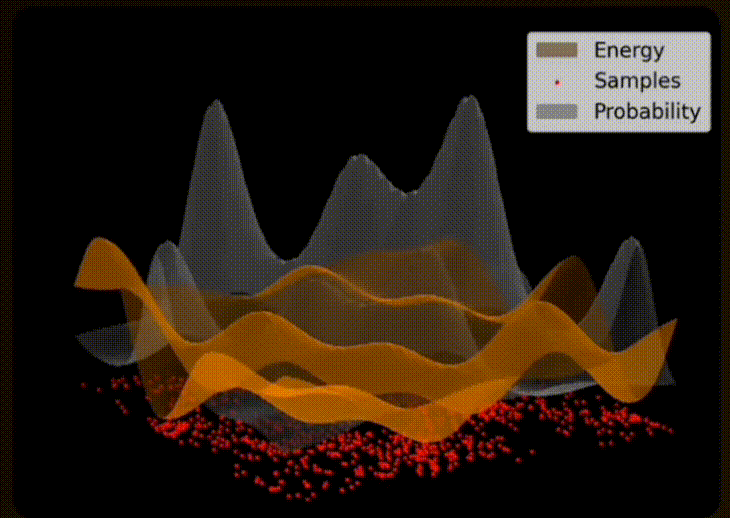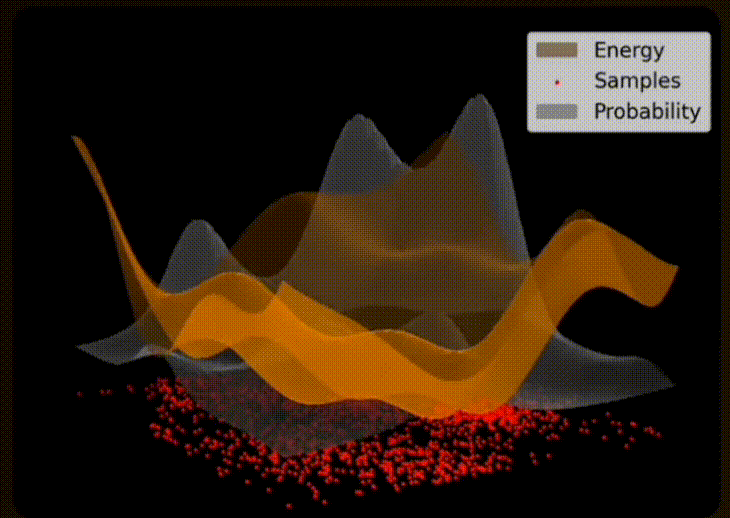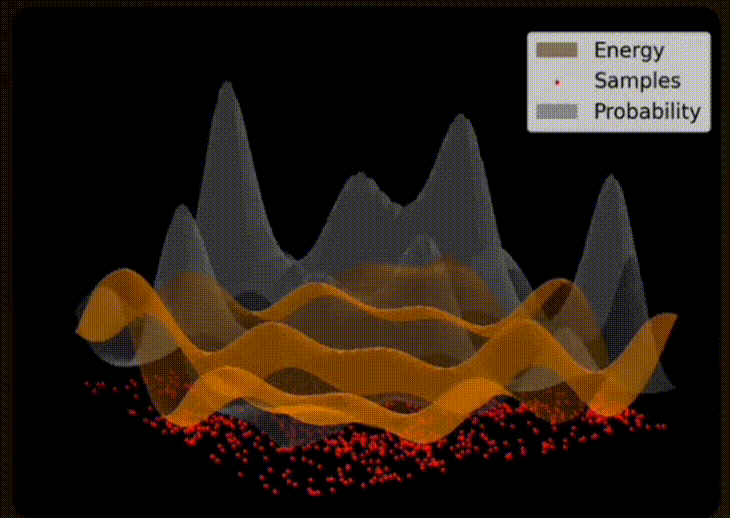
From an Extropic presentation at SF Deep Tech Week
10. Sampling
The energy (i.e. electron distributions) of each state is measured. Probabilities are derived from the energy of each state via a formula (i.e. Boltzmann Distribution). States with lower energy have higher probabilities via the Boltzmann Distribution. A state is selected from the energy landscape, with more probable states being more likely to be selected.
11. Analog-to-Digital Conversion
The selected state is measured and converted back into vectors.
12. Tokenization
Vectors are converted back into tokens.
13. Detokenization
Tokens are mapped back into text, and then outputted.
∞. Updating Energy Landscape
The output is incorporated into the previous embeddings and then basis functions are reapplied, updating the energy landscape with the new output, which then reaches a new thermal equilibrium with the new contributions from the output.
Why is this Significant
Scaling
As you scale parameter count, training compute, and inference time, models improve in performance. Additionally, there does not seem to be an upper bound to this relationship. By continuing to scale, we theoretically could create artificial superintelligence.
From an article by Dr. Leon Eversberg
Limitations to Scaling Compute
There are soft ceilings to scaling AI systems. A soft ceiling represents a limit that could be surpassed, albeit with significant effort and/or resources. This limit may soon be reached, especially as AI systems continue to be scaled exponentially.
Moore’s Wall
Moore’s Law is the trend where the number of transistors on a chip doubles every two years. There is also a limit to this relationship as when transistors become sufficiently small, the distance between them becomes so small that quantum effects begin to interfere (e.g. electron tunneling)., among other issues. We are seemingly nearing this limit, thus need alternative approaches to further increase compute.
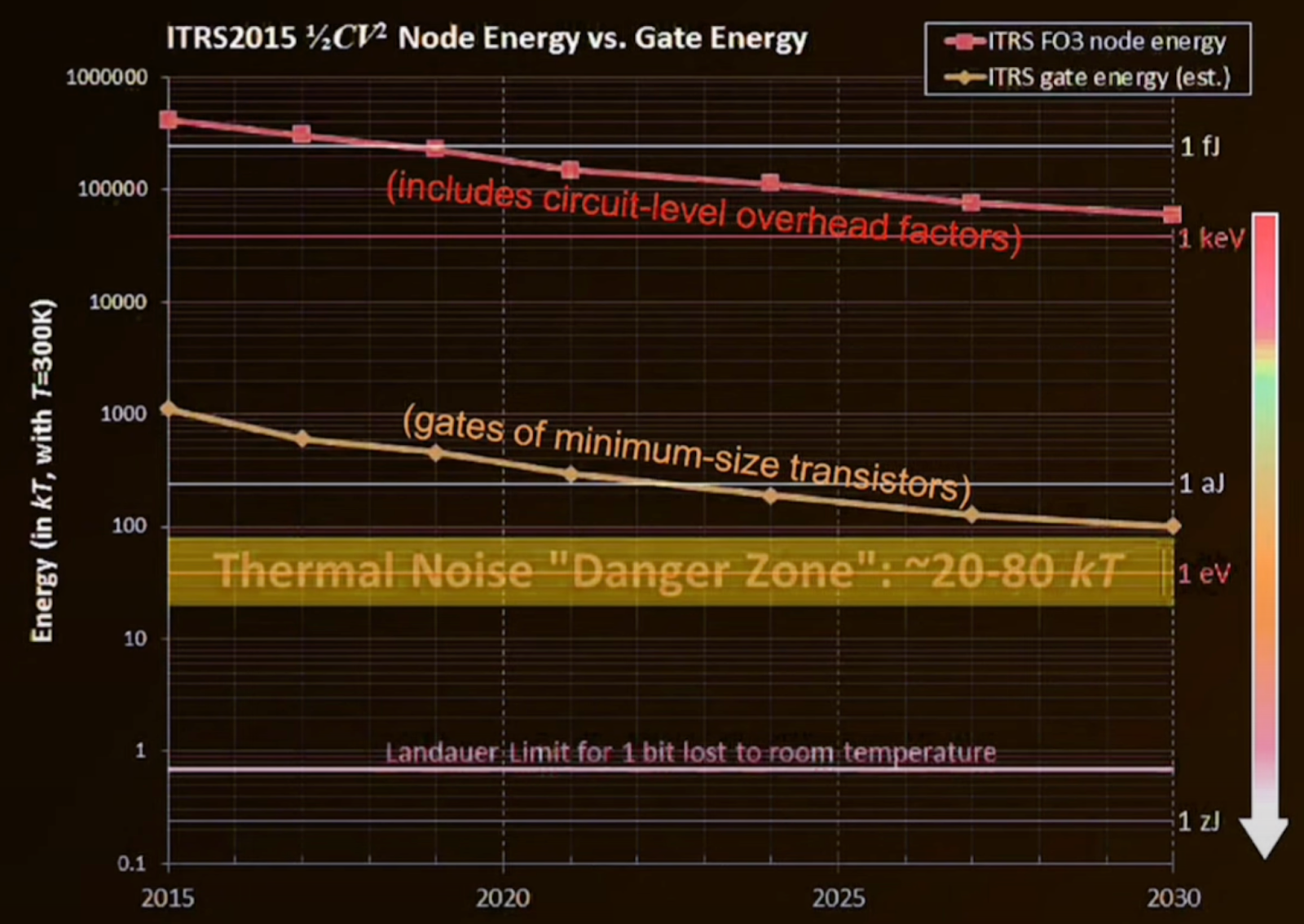
From an Extropic presentation at SF Deep Tech Week
Energy
AI systems require an immense amount of energy, and these will only rise as we continue to scale.
The exponential scaling of energy requirements will also scale energy expenses exponentially. Energy production will also need to be scaled and even with cost aside, it takes a significant amount of time to scale energy infrastructure.
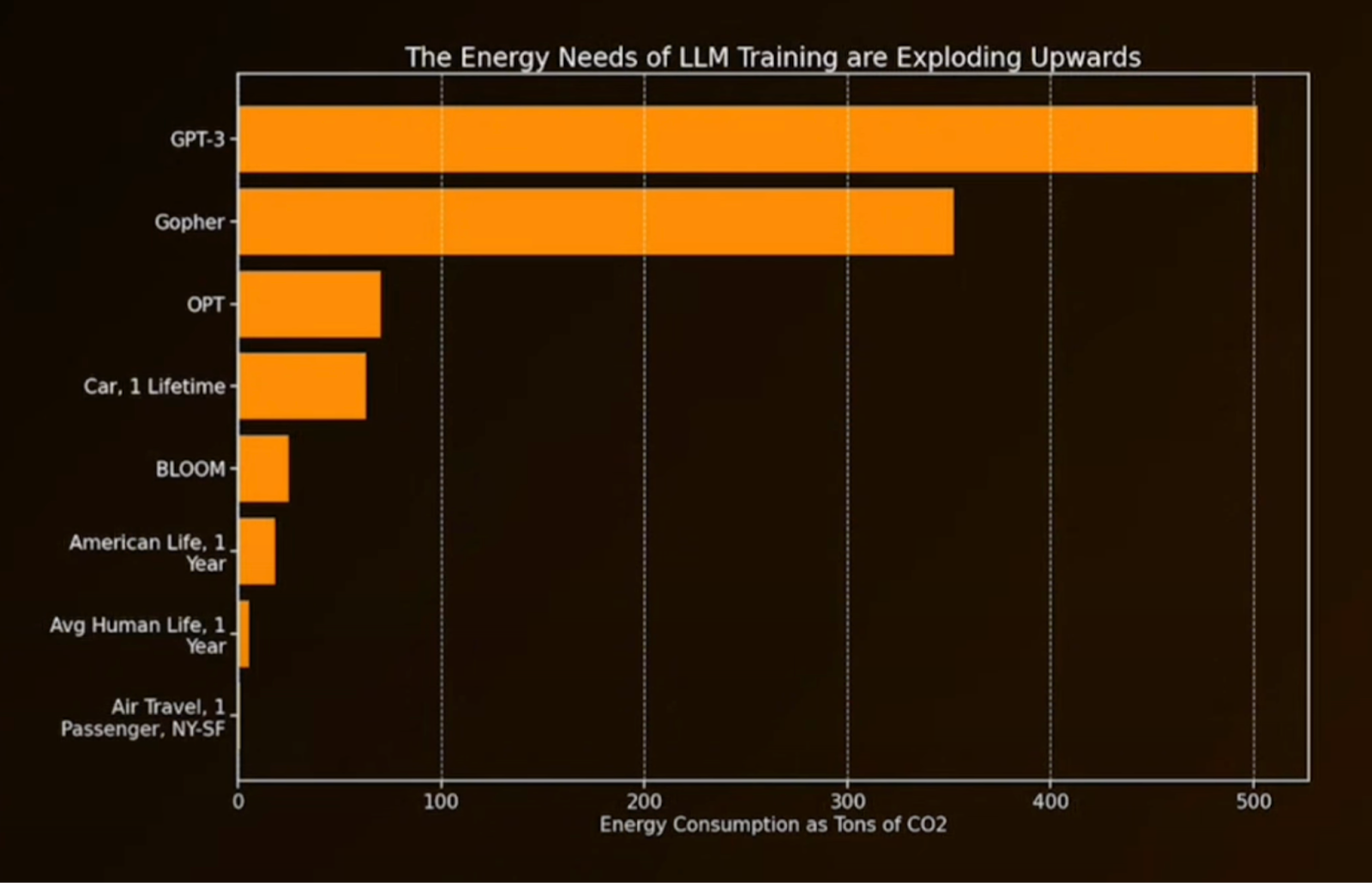
From an Extropic presentation at SF Deep Tech Week
Infrastructure
AI systems have had to physically scale in order to accommodate the training of larger AI models. The physical scaling of infrastructure presents another soft ceiling as this infrastructure is quite expensive, requires waiting for components to be delivered (as there is a significant backlog due to extreme demand for SOTA GPUs), and of course requires time to construct. For example, xAI’s recently completed Colossus supercluster is composed of 100k H100 GPUs, cost $3-4B, and took 122 days to construct.
Thermodynamic Computing as a Catalyst
Computational Density
When run on traditional computers, transformer models apply many millions of isolated transformations to the input to predict the output. Conversely, transformers on thermodynamic systems only apply a few transformations to the input as the transformations applied are not applied individually and instead are applied holistically as a group (i.e. energy landscape). This results in a token prediction that is more energy efficient and faster.
Additionally, as the increased density allows for equally sized models to be run with less calculations, less compute is needed to perform calculations. Not only does this allow for models to be run with less compute, but also for larger models to be run and/or trained with the same compute.
Lastly, the higher computational density in thermodynamic systems allows them to handle more complex patterns, including rare “tail events.” Traditional systems require significant computational resources to address these edge cases due to the isolated nature of transformations. In contrast, thermodynamic systems process information holistically, enabling them to capture rare or complex occurrences more efficiently. This allows for greater complexity without a corresponding increase in energy consumption or processing time, making them well-suited for intricate tasks.
Natural Energy Minimization
In traditional computers, transistors must be charged in order to be switched to their “on” state, and then to switch to their “off” must be discharged. The charging of the transistors requires an energy input and the discharge of the transistors results in the loss of that inputted energy as it is dissipated as heat.
Conversely, thermodynamic computers perform their computations naturally without the need to charge and discharge transistors. Instead, electrons naturally distribute themselves throughout the circuit, thereby naturally performing the computation for the energy landscape.
This distinction once again results in a more efficient system. Additionally, there is the benefit of less heat generation thus reduced cooling needs which are very significant in the current AI systems.
Updating Landscapes
In thermodynamic systems, after predicting a set of tokens, those tokens can be subsequently used to update the existing landscape. Conversely in classical computing the entire input, original and new tokens, would need to be re-fed through the entire process. As a result of this distinction, subsequent inputs on thermodynamic systems are more energy efficient and faster, with this gap growing as the length of the entire input grows.
Physical Model Implementation
In order to run transformer models, the model must first be loaded (i.e. from storage and into VRAM). This can be quite demanding as models are immense with trillions of parameters. However, even when loaded, continuous power is required to keep the model loaded (i.e. in VRAM). Conversely, as the model is physically encoded in thermodynamic computers, no continuous power is required, thus once again resulting in an energy efficiency improvement. Additionally, a large amount of memory (i.e. VRAM) is not needed, which is quite beneficial as high memory GPUs are currently incredibly expensive.
Silicone Based Computing
The chip fabrication industry is incredibly mature, producing well over 1T chips per year. Even considering the above advantages of thermodynamic computers, if these chips could not be produced using the same infrastructure, it would be quite expensive and time-consuming for the industry to shift production. Luckily, these thermodynamic chips are also silicon based and able to be designed using existing chip fab technologies.
Degrees of Superiority
Energy Efficiency
The aforementioned energy efficiency advantages afforded to Extropic’s thermodynamic computers allow for training and inference of transformers more efficiently than GPUs by a factor of 107 to 1013.
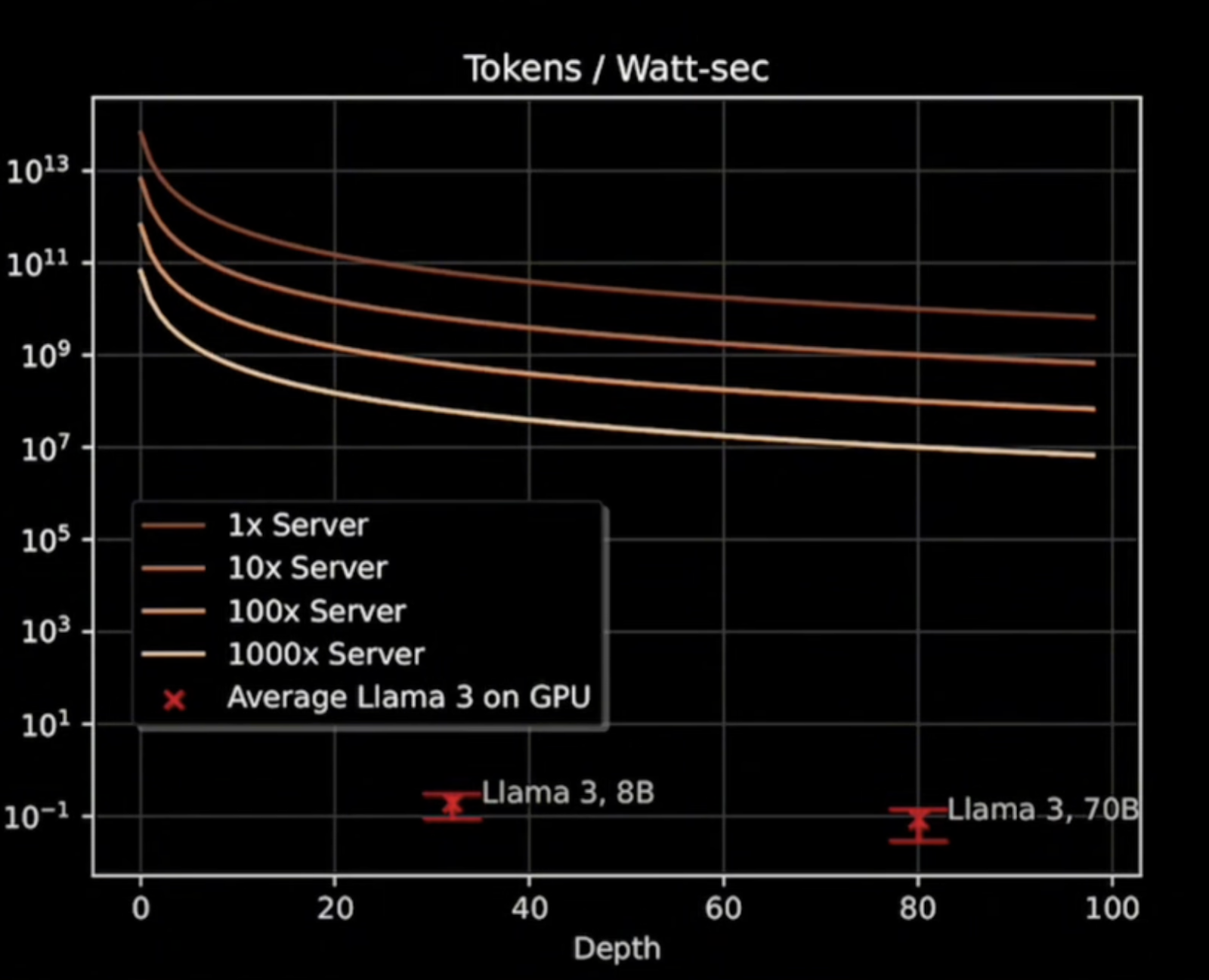
From an Extropic presentation at SF Deep Tech Week
Based on simulations, use of superconducting substrate, and only considering energy consumption of chip
Speed
The advantages related to speed would allow Extropic’s thermodynamic systems to conduct inference of transformer models at roughly 1000-10,000x the speed of GPUs.
Conclusion
Thermodynamic systems have the potential to completely revolutionize the AI space and the world by allowing for inconceivably large improvements to the speed and cost of current AI models but more importantly for allowing the training of models well beyond the size and capabilities of today’s leading models.